2.2 Passive Crawling & Spidering
Crawling and Spidering are techniques used to automatically browse and index web content, typically performed by search engines or web crawlers. Here's a breakdown of each:
Crawling
Crawling is the process of systematically browsing the web to discover and index web pages.
A crawler, also known as a web spider or web robot, starts with a list of seed URLs and then follows hyperlinks from one page to another, recursively.
Crawlers retrieve web pages, extract links from them, and add new URLs to their queue for further crawling.
They often adhere to a set of rules specified in a file called robots.txt to determine which parts of a website they are allowed to crawl and index.
We can utilize Burp Suite's passive crawler to map out the web app and understand its structure (navigating on website an retrieve the site map).
Spidering
Spidering is a term often used interchangeably with crawling, referring to the automated process of fetching web pages and following links.
It derives from the analogy of a spider weaving a web by moving from one location to another and creating connections.
Spidering involves systematically traversing the web, exploring web pages and their links to index content for search engines or other purposes.
Spidering algorithms may vary based on the specific objectives, such as optimizing for depth-first or breadth-first traversal, or prioritizing certain types of content.
We can utilize Burp Suite Pro or OWASP ZAP's Spider to automate the process of spidering a web application to map out the web app and understand its structure.
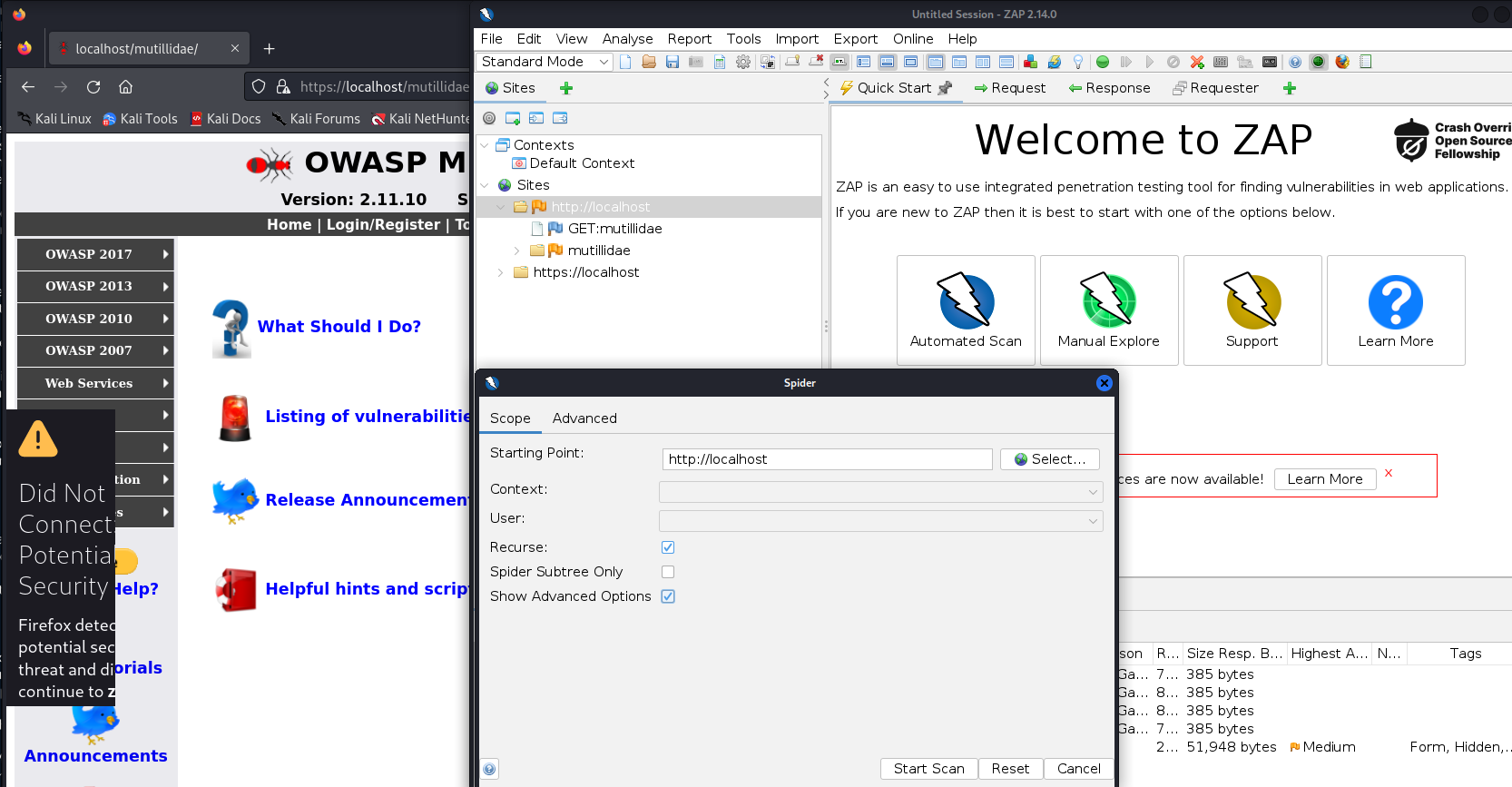
Spidering with OWASP ZAP
Abilitate Foxy Proxy on browser (Firefox)
Refresh webpage to retrieve Sites Link on ZAP
Click on Tools -> Spider
Select URL and abilitate recurse
Start Scan
We obtained more URIs and we can save them into .csv format for a better exportation and manipulation.