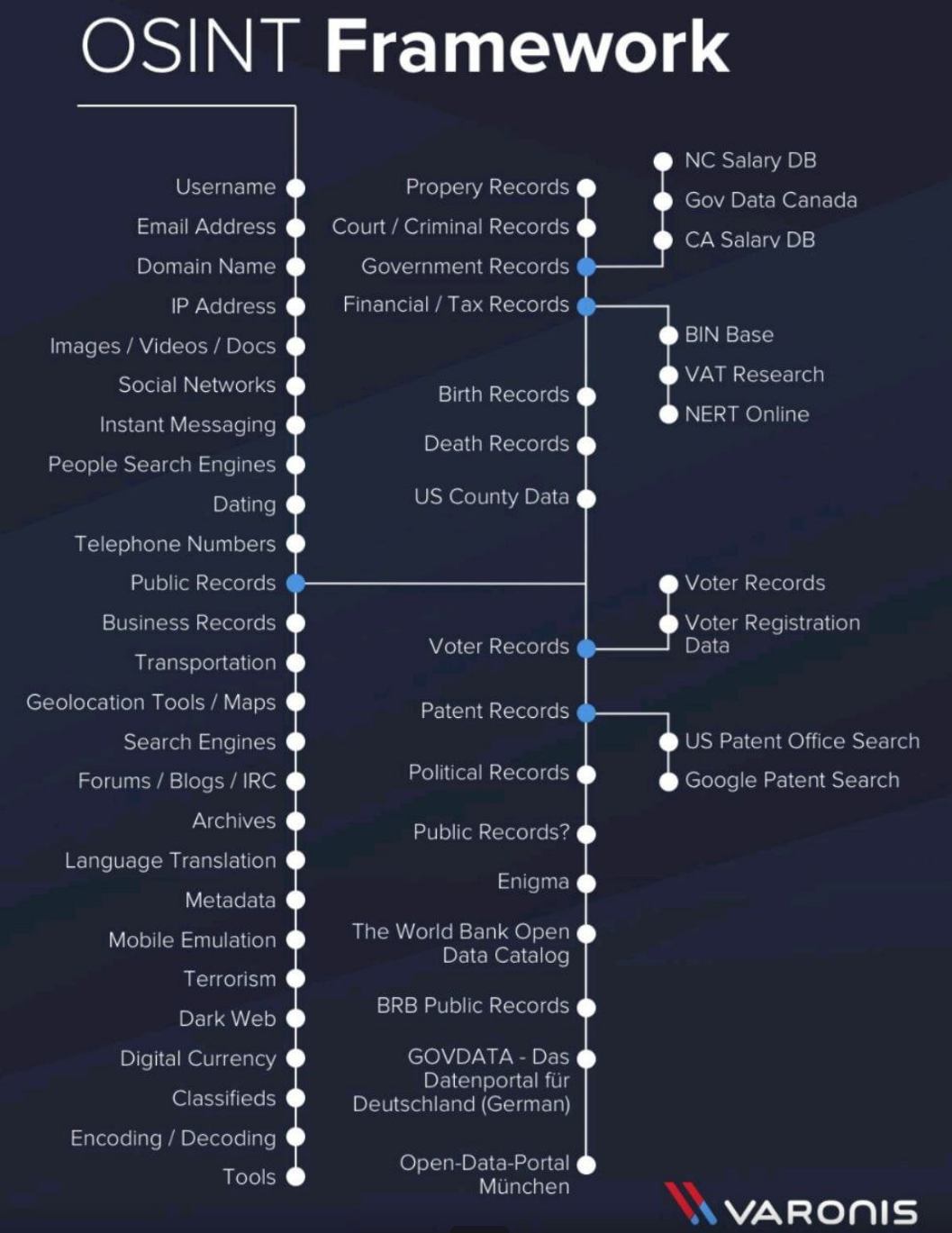
# 2.1 Information Gathering
What is Information Gathering?
* The initial phase of any penetration test involves information gathering. This step revolves around gathering data about an individual, company, website, or system that is the target of the assessment.
* Success in the later stages of a penetration test is closely linked to the extent of information gathered about the target. In other words, the more comprehensive the data collected, the higher the chances of success.
* Information gathering can be categorized into two main types: passive and active.
{% content-ref url="" %}
[1.1 Information Gathering](https://app.gitbook.com/s/PNcjhcAuvH4mlZKYrNu3/readme/assessment-methodologies-and-auditing/1.1-information-gathering)
{% endcontent-ref %}
## Information Gathering
* The initial phase of any penetration test involves information gathering. This step revolves around gathering data about an individual, company, website, or system that is the target of the assessment.
* Success in the later stages of a penetration test is closely linked to the extent of information gathered about the target. In other words, the more comprehensive the data collected, the higher the chances of success.
* Information gathering can be categorized into two main types: passive and active.
## Information Gathering on Web Applications
When focusing on web applications, information gathering involves collecting data related to the target web application, its architecture, technologies used, and potential entry points for exploitation. This phase is crucial for uncovering vulnerabilities and weaknesses specific to web applications.
## Passive Information Gathering
#### Website Recon & Footprinting
**Reconnaissance**, aka "recon", (often associated with information gathering) involves collecting information about a target system or organization using passive methods. This means gathering data without directly interacting with the target system, network, or organization.**Footprinting** is a specific phase of reconnaissance that focuses on gathering detailed information about a target system, network, or organization in order to create a "footprint" of its digital presence. This involves both passive and active methods to collect data about IP addresses, domain names, network infrastructure, organization structure, technical contacts, and more.In a website, we try to seek information about:
* IP address,
* Directories hidden from search engines,
* Names,
* Email address,
* Phone numbers,
* Physical Addresses,
* Web technologies being used.
#### Web App
For web applications, this may include techniques such as:
* Identifying domain names and domain ownership information.
* Discovering hidden/disallowed files and directories.
* Identifying web server IP addresses & DNS records.
* Identifying web technologies being used on target sites.
* WAF detection.
* Identifying subdomains.
* Identify website content structure.
**Whatis**
The first thing that we can do is perform a **DNS lookup** by **whatis** command:whatis website\_urlto find information about website, for example if we have two address: it can means that website is behind a firewall/proxy.Another good activity to do first to start is find website/**robotx.txt** fileThe "**robots.txt**" file is a text file used by websites to communicate with web crawlers and search engine bots about which parts of the site should not be crawled or indexed. It is a standard used to provide instructions to web robots, also known as web crawlers or spiders, that automatically navigate and index websites for search engines like Google, Bing, and others.Here are some key points about the "robots.txt" file:
1. 1.**Purpose**: The main purpose of the "robots.txt" file is to control the behavior of web crawlers on a website. It allows website administrators to specify which parts of their site should not be crawled by search engine bots.
2. 2.**Location**: The "robots.txt" file is typically placed in the root directory of a website. For example, if your website's domain is "example.com," the "robots.txt" file would be accessible at "."
3. 3.**Syntax**: The "robots.txt" file uses a simple syntax to specify user-agent (crawler) directives and disallow rules. User-agents are identifiers for specific web crawlers. Common user-agents include "Googlebot" for Google's crawler and "Bingbot" for Bing's crawler.
4. 4.**Directives**:
* **User-agent**: Specifies the web crawler to which the following rules apply.
* **Disallow**: Instructs the specified user-agent not to crawl the specified URL paths.
* **Allow**: Overrides a disallow rule for specific URL paths.
* **Sitemap**: Specifies the location of the XML sitemap file that contains a list of URLs on the site.
5. 5.**Example**: Here's an example of a simple "robots.txt" file:User-agent: \*Disallow: /private/Disallow: /temp/Allow: /public/Sitemap: this example, the asterisk (\*) as the user-agent means the rules apply to all crawlers. It disallows crawling of the "/private/" and "/temp/" directories while allowing crawling of the "/public/" directory. It also specifies the location of the sitemap.
#### XML Sitemap
Another good resource is **XML Sitemap** website/sitemap\_index.xml, that provide an organized way of indexing the website.
To identify website technology or content management system used in a website, we can use:
Add*-*ons:
* BuilWith,
* Wappalyzer,
*Cmd app:*
* WhatWeb
If we wanted to download the entire website and analyze the source code locally, we can use:
* [HTTrack](https://www.httrack.com/) Website Copier
#### Whois
[**Whois**](https://who.is/) is a command and network protocol used to obtain detailed information about an internet domain name or an IP address. The term "whois" comes from the question "Who is?"
When you execute the "whois" command on a domain name or an IP address, you request information about the domain's owner, the registrar (the organization responsible for managing the domain registration), registration and expiration dates, technical and administrative contacts associated with the domain, and other related information.
For example, if you want to find out the registration details of a domain like "example.com," you can run the command "whois example.com" to retrieve relevant information about that domain.
#### Netcraft
[Netcraft](https://www.netcraft.com/) is a website tool used to do website recon, in details can be used for::
**Website Analysis**: Netcraft offers tools and services to analyze websites. You can use their tools to gather information about a website's hosting provider, domain history, technology stack, and other related information.
**Security Research**: Netcraft monitors and reports on internet security threats, including phishing attacks, malware distribution, and other online scams. They maintain a database of phishing websites and offer browser extensions that help users detect and avoid potentially harmful websites.
**Server Surveys**: Netcraft conducts regular surveys to gather data about web servers and internet technologies. They track trends in web server software usage, operating systems, and other related statistics. This information can be valuable for businesses and researchers to understand the landscape of internet infrastructure.
**Domain and Hosting Information**: Netcraft provides tools to retrieve information about domain registrations, IP addresses, and hosting providers. This can be useful for investigative purposes or for businesses looking to gather competitive intelligence.
**Cybersecurity Services**: Netcraft's services include monitoring for DDoS attacks, phishing attempts, and other security threats. They offer services to help organizations identify and mitigate online threats to their websites and online services.
**Data Visualization**: Netcraft often presents its data and research through visualizations and reports. These can be helpful for understanding internet trends, security threats, and other relevant information.
**Historical Data**: Netcraft's historical data can be used to track changes in websites and online infrastructure over time. This can be useful for businesses looking to analyze their own or their competitors' online presence.
1. **Local DNS Resolution**: The hosts file provides a way to manually define hostname-to-IP mappings without relying on external DNS servers. This can be useful for testing and development purposes, as well as for mapping local network resources.
2. **Ad Blocking and Content Redirection**: Users can use the hosts file to block access to certain websites by redirecting their domain names to a non-existent or local IP address. This is often used to block ads and unwanted content at the local level.
3. **Avoiding DNS Lookup Delays**: Since the hosts file is consulted before DNS queries are made, it can provide faster resolution for frequently accessed domains, improving the speed of network operations.
4. **Local Network Customization**: In small local networks or closed environments, administrators can use the hosts file to ensure that specific hostnames resolve to specific IP addresses, even if those hostnames are not registered in the global DNS.
### Subdomain Enumeration
#### What is Subdomain?
A subdomain is a part of a larger domain in the Domain Name System (DNS) hierarchy. In a domain name like "example.com," the "example" is the main domain, and a subdomain would be a prefix added to it, such as "sub.example.com." Subdomains are used to organize and navigate different sections or services within a domain, and they allow for better management and segregation of content or functionality.
The scope of subdomains is to create a structured hierarchy within a domain and provide a way to categorize and manage various aspects of a website or online presence. Here are some common use cases and benefits of using subdomains:
* Content Organization: Subdomains can be used to organize different types of content or services. For example, a website might have "blog.example.com" for a blog section and "shop.example.com" for an online store.
* Geographical Segmentation: Companies with a global presence might use subdomains to serve localized content, like "us.example.com" for the U.S. and "uk.example.com" for the United Kingdom.
* Departmental Separation: Large organizations can use subdomains to separate different departments or teams. For instance, "hr.example.com" could be used for the Human Resources department.
* Testing and Development: Subdomains are often used for testing new features or development versions of a website. For example, "dev.example.com" might host a development version.
* Mobile and App Access: Subdomains can be used to provide access to mobile or app-specific content. "m.example.com" might be used for the mobile version of a site.
* API Endpoints: Subdomains can be dedicated to hosting APIs, such as "api.example.com," providing a clear separation of API resources from the main website.
* Tracking and Analytics: Subdomains can be used to set up tracking and analytics services separately from the main website, helping to manage data more effectively.
* Security and Isolation: Subdomains can offer a level of isolation between different parts of a website. If one subdomain is compromised, it might not automatically jeopardize other subdomains.
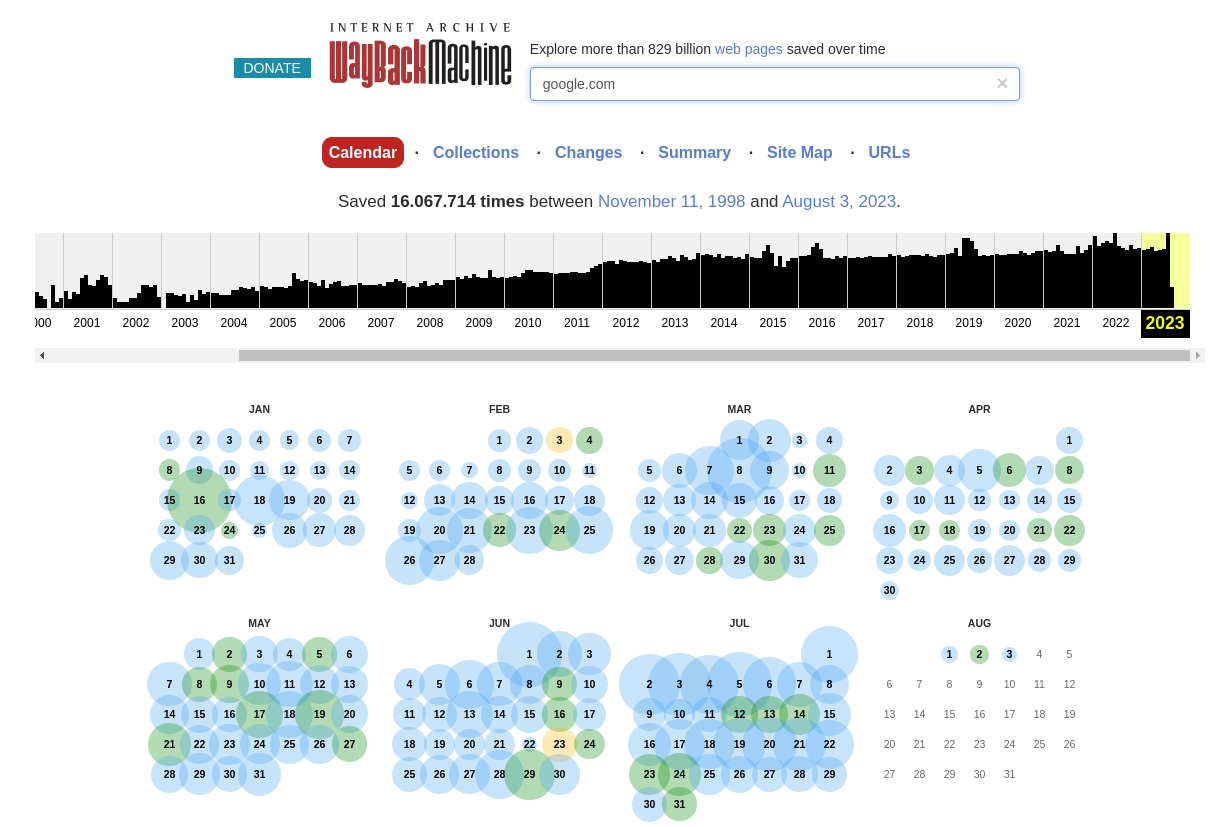
The [**Wayback Machine**](https://archive.org/web/)**,** operated by the Internet Archive, is a digital archive that captures and stores snapshots of websites and web pages over time. Its primary purpose is to preserve the history of the internet by archiving web content, allowing users to access past versions of websites and track changes that have occurred over the years.
The scope of the Wayback Machine includes:
* **Historical Website Access**: The Wayback Machine provides a valuable resource for researchers, historians, and the general public to access and explore the historical content of websites. It allows users to see how websites looked and what content they contained at different points in the past.
* **Content Verification**: The archived snapshots on the Wayback Machine can serve as a means to verify information and claims made on websites. If a website's content changes or is taken down, the archived version can still be accessed for reference.
* **Legal and Regulatory Compliance**: Archived versions of web pages can be used as evidence in legal cases or to demonstrate compliance with certain regulations at specific points in time.
* **Website Evolution**: Website owners and developers can use the Wayback Machine to track the evolution of their websites, review design changes, and identify past content.
* **Recovery of Lost Content**: If a website experiences data loss or accidental deletion, the Wayback Machine might have archived versions that can help recover lost content.
* **Research and Academic Study**: Researchers and scholars can use the Wayback Machine to study the evolution of online trends, technologies, and information dissemination.
* **Cultural and Social Analysis**: The archived web content can offer insights into the cultural and social changes reflected in online communication over time.
* **Digital Preservation**: The Wayback Machine plays a crucial role in digital preservation by preventing the loss of valuable online content due to website closures, changes, or technological obsolescence.
example of usage for google.com
### Email Harvesting
**Email harvesting** refers to the process of collecting or extracting email addresses from various sources, typically with the intention of building a list for marketing, communication, or other purposes. This practice involves using automated tools, scripts, or manual methods to gather email addresses from websites, online platforms, or databases. Email addresses obtained through email harvesting are often used for email marketing campaigns, spamming, phishing attacks, or other unsolicited communications.
Email harvesting can be conducted in various ways:
* **Web Scraping**: Automated bots or scripts crawl websites and extract email addresses from publicly accessible pages, such as contact pages, forums, comment sections, or user profiles.
* **Search Engine Queries**: Attackers might use specific search queries, also known as "Google Dorks," to find web pages containing email addresses, and then extract them.
* **Online Directories**: Some email harvesters target online directories, business listings, or social media platforms to gather email addresses associated with individuals or organizations.
* **Spamming and Phishing**: Cybercriminals may harvest email addresses for the purpose of sending spam emails or conducting phishing attacks to trick recipients into revealing personal information.
* **Data Breaches**: In some cases, attackers obtain email addresses through data breaches of websites, databases, or organizations, where sensitive information is leaked.
* **Credential Stuffing**: Attackers use harvested email addresses to perform credential stuffing attacks, where they use lists of email and password combinations to gain unauthorized access to online accounts.
## Active Information Gathering
{% embed url="" %}
Active information gathering involves interacting directly with the target system to collect data. For web applications, this may involve techniques such as:
* Downloading & analyzing website/web app source code.
* Port scanning & service discovery.
* Web server fingerprinting.
* Web application scanning.
* DNS Zone Transfers.
* Subdomain enumeration via Brute-Force.
#### Net Discovery
Another good tool to do host discovery is: NetDiscovery, that permits to do:
1. **Network Discovery:** Netdisco uses various methods, such as SNMP (Simple Network Management Protocol) and ARP (Address Resolution Protocol) scanning, to discover devices on the network and collect information about them.
2. **Device Tracking:** It tracks the physical location of devices based on the switch and port they are connected to. This can be useful for troubleshooting and inventory management.
3. **Port and VLAN Management:** Netdisco helps in managing port configurations, tracking the status of ports, and managing VLAN (Virtual LAN) assignments.
4. **IP Address Management:** It can manage IP address allocations and assist in tracking IP address usage and assignments.
5. **Visualization:** Netdisco provides visual representations of network topologies and connections, making it easier to understand the layout of the network.
6. **Historical Data:** The tool can keep historical data about device and network changes, aiding in troubleshooting and understanding network behavior over time.
## Other Resources
{% content-ref url="" %}
[1.2 Footprinting & Scanning](https://app.gitbook.com/s/PNcjhcAuvH4mlZKYrNu3/readme/assessment-methodologies-and-auditing/1.2-footprinting-and-scanning)
{% endcontent-ref %}
{% content-ref url="" %}
[2 - Footprinting & Recon](https://app.gitbook.com/s/iS3hadq7jVFgSa8k5wRA/practical-ethical-hacker-notes/main-contents/2-footprinting-and-recon)
{% endcontent-ref %}
{% content-ref url="" %}
[1.3 Enumeration](https://app.gitbook.com/s/PNcjhcAuvH4mlZKYrNu3/readme/assessment-methodologies-and-auditing/1.3-enumeration)
{% endcontent-ref %}